Architecture
Cutestudio's EMBER embedded webserver is a multi-layered piece of C software that is written in a very modular fashion.
Structured, modular design
The web server sits on a series of tuned adaptive buffers and interacts with the page/object sources via our CTL layer. The CTL allows the in-page scripting and custom object content generation.
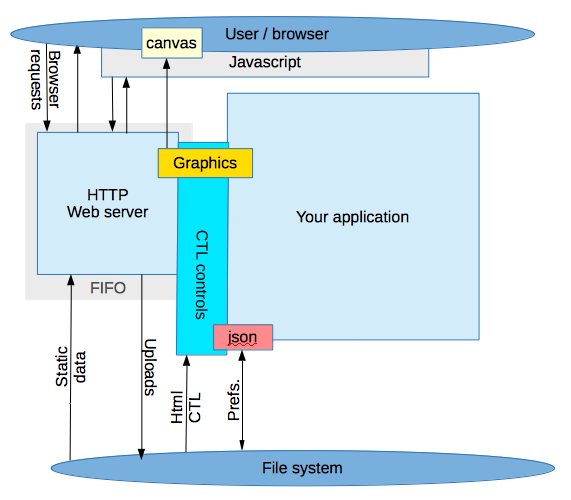
We supply built in CTL objects to allow a wiki style page generation (Silk), interactive controls + settings database (Control), and a web graphics context for the easy creation of graphs, waveforms etc on your pages.
Additionally static objects like images etc are served on demand as for any website so there is an air of familiarity with the deployemnt of your web solution but with Silk, Control and WGC results can be achieved very fast.
The memory routines actually live in the accompanying Cutestudio utility library for Ember, a rather useful library that moves all the basic, low level routines away from the business of serving webpages.
Below some aspects of the memory design are discussed.
Fast and fragmentation free CG based Memory architecture in C
Because a webserver is stateless and has to serve a number of pages and streams on a repeated basis one of the fundamental concerns is that of memory reliability and usage.
Traditionally a C or C++ program uses regular heap memory via malloc() and free() (C++ just builds on this but underneath the mechanism is essentially the same). In C this means that each item has to be tracked and freed after each page is served, so there is some overhead in this process and there are two problems:
- Some items may be missed due to programming errors and therefore 'leak' memory over time
-
Due to the nature of malloc the memory can become fragmented and a program can end up using more memory over time simply due to the 'holes' being of the wrong size. This is a particular issue with streaming systems unless care is taken.
To prevent these issues there are two subsystems in Ember that deal with allocation:
- Popular block size list allocation and re-use.
-
Garbage collection
1. Popular blocksize management
This is simply a system that manages blocks or different sizes for various lists that prevents the need to continually free and malloc the blocks. For popular objects instead of simply using malloc and free Ember has the functions:
// A generalised system for re-using allocated blocks to prevent memory fragmentation and delays
typedef enum {
UTIL_BLOCK_NEVERCLEAN, // Like malloc
UTIL_BLOCK_ALWAYSCLEAN // Always return a cleaned memory space
} UTIL_BLOCKTYPE;
extern void *util_block_alloc(int size, const char *name, UTIL_BLOCKTYPE type, int *pcounter);
extern void util_block_release_base(void *item, int size); |
The programmer / Ember then merely requests blocks of a size and then hands them back, the block manager simply deals with storing the spares and re-allocating them as required. Thus these blocks are only allocated once (preventing fragmentation) and rapidly pulled off the spares list as needed.
This block system is also used as a foundation for the GC described below, a groundbreaking GC system possibly unique to Ember.
2. Efficient GC (Garbage Collection) in C
The advantages of garbage collection is as follows:
- Nothing gets missed by the programmer
-
Nothing has to be explicitly tracked by the programmer
-
String manipulation becomes easy because allocations can be done on a casual as-needed basis because the original string doesn't need to be freed or tracked.
The disadvantages are all down to implementation defects that arise from the outdated philosophy that the garbage collector does all the work to decide what to free, and so GC tends to be slow, CPU intensive and complex.
The Ember GC however uses a different philosphy of storing the memory in the dustbin to start with, so when it's collected the system merely has to recycle the dustibins. Yes, it's that simple. That not only makes the GC fast, it actually makes it much much faster than traditional free()s because the memory is recycles dustbin by dustbin rather than item by item.
So all the ember system does is to use a context to identify the dustbin/bins for the particular operation at hand, so when the page is served they can simply be collected:
// NEW (GC collected allocations)
extern void *util_new_noclear(int size, void *context); // Does not clear the memory it allocates (faster)
extern void *util_new(int size, void *context);
// Tidy / free
extern void util_garbage_collect(void *context); // When a session closes..
// GC string ops
extern char *util_strdup_new(const char *sval, void *context);
: |
Because of various optimisations such as tracking the current new() block etc. the allocation is simpler and faster than the system malloc() as all it does it allocate - no need for search for holes to use, it simply has to decide:
- Allocate in the current block if there is space
-
Create a new block
-
Do a custom sized allocation for the rare items that are > blocksize in use
Using a signature for memory check integrity the Ember new() allocation is a simple, rapid, linear allocation across blocks that are used for the current task, and then collected when the page serve ends or the data is not needed anymore.
For large static data like JSON data etc the static address of the data structure pointer is used as the context, so when the data is refreshed the GC is simply run and the new() data built up again. I.e. the GC is not limited to page serving transactions, it's rather good at static data structures too. Because of the underlying block nature of the memory organisation a refresh of a complex data structure need not even call malloc, it can simply reuse the collected blocks.
Garbage collection is therefore extremely simple, the blocks for the context are identified and handed back to the blocksize manager for reuse in a very rapid, simple operation and the entire memory used is now available for other threads and pages to use.
Advantages of the Ember C based GC
- Allocation is faster than using malloc()
-
String operations are much easier
-
Memory leaks are eliminated
-
Collection is significantly faster than free() ing all the separate little items
Note this also saves the effort of traversing lists etc. when freeing so the speedup is quite dramatic.
-
Eliminates memory fragmentation, an issue with long running webservers and streamers
So Cutestudio's technology is not just a fast GC system, it's actually faster than traditional C memory systems.
An example of the block-based system in use in SeeDeClip4:
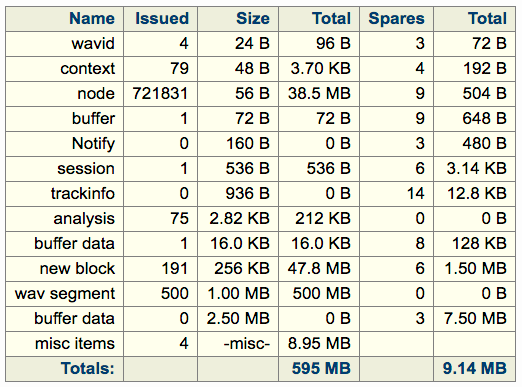
The 'new block' items are those used by the GC memory system, the size is arbitrary but in this case a block size of 256k was chosen as most items fit in there and it's a small enough size to not waste much space when the webserver is busy serving multiple http requests.
It can be seen that 6 are sitting on the 'spares' queue for instant use, most of the 191 issued blocks are for static data (JSON node data) for tracking various audio parameters of a music library.
The other blocks are managed by the popular blocksize manager and are allocated only once, after that they merely hop between lists within the program and spare lists for immediate re-use. This saves calls to malloc() and free() and fragmentation issues as they are allocated once and instantly available from the spares list as needed. Blocks of a particular size can be shared between various lists, only the size determines
Note: Lists in use by the program are generally managed via universal hash-table functions for fast access.
|
|
|
